LayerNorm
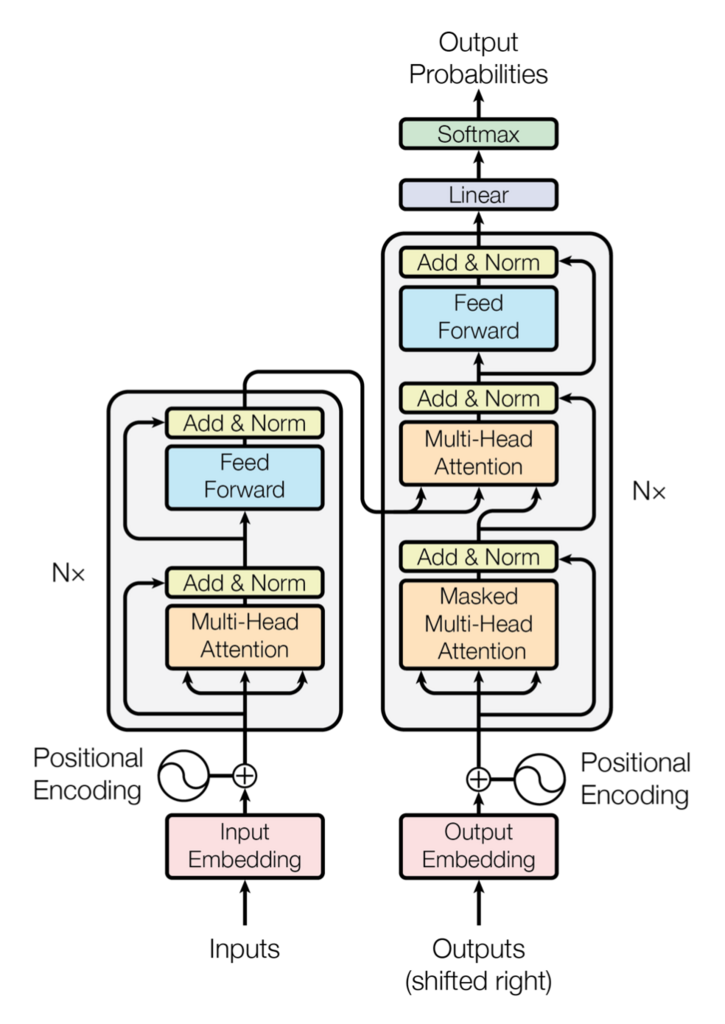
MultiHeadedAttentionとPositionwiseFeedForwardの後には、それぞれ 残差結合(Add) と Layer Normalization(Norm)がある。(下図の「Add & Norm」)
Layer Normalizationの実装
作って理解する Transformer / Attention から引用。
画像処理系の Deep Learning では Batch Normalization が有名ですが、 Transformer では Layer Normalization を使います。
Layer Normalizationの実装例。 OpenNMT-pyでは、PyTorchのnn.LayerNorm を使う。
class LayerNormalization(tf.keras.layers.Layer): def build(self, input_shape: tf.TensorShape) -> None: hidden_dim = input_shape[-1] self.scale = self.add_weight('layer_norm_scale', shape=[hidden_dim], initializer=tf.ones_initializer()) self.bias = self.add_weight('layer_norm_bias', [hidden_dim], initializer=tf.zeros_initializer()) super().build(input_shape) def call(self, x: tf.Tensor, epsilon: float = 1e-6) -> tf.Tensor: mean = tf.reduce_mean(x, axis=[-1], keepdims=True) variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True) norm_x = (x - mean) * tf.rsqrt(variance + epsilon) return norm_x * self.scale + self.bias
Layer Normalizationの説明
Layer Normalizationの説明は、深層学習界の大前提Transformerの論文解説! が詳しい。
以下、そこからの引用
- Batch Normalization(上図真ん中)は同一チャネルをミニバッチに跨って正規化する
- Layer Normalizationはミニバッチ全体に及んで正規化するのではなく、各データそれぞれで正規化する。
- Transformerでいうとミニバッチ内の各データというのは各文章に対応する。
- 1文例えば256単語あるとしたらその256単語に跨って正規化する